

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
§管理数据库演变
当您使用关系型数据库时,您需要一种方法来跟踪和组织您的数据库模式演变。通常情况下,您需要更复杂的方法来跟踪数据库模式更改的情况有很多。
- 当您在一个开发人员团队中工作时,每个人都需要了解任何模式更改。
- 当您在生产服务器上部署时,您需要一种可靠的方法来升级您的数据库模式。
- 如果您在多台机器上工作,您需要保持所有数据库模式同步。
§启用演变
将 evolutions 和 jdbc 添加到您的依赖项列表中。例如,在 build.sbt 中
libraryDependencies ++= Seq(evolutions, jdbc)
§使用编译时 DI 运行演变
如果您使用的是 编译时依赖项注入,您需要将 EvolutionsComponents 特性混合到您的蛋糕中,以访问 ApplicationEvolutions,它将在实例化时运行演变。EvolutionsComponents 需要定义 dbApi,您可以通过混合 DBComponents 和 HikariCPComponents 来获得。由于 applicationEvolutions 是 EvolutionsComponents 提供的延迟 val,因此您需要访问该 val 以确保演变运行。例如,您可以在 ApplicationLoader 中显式访问它,或者从另一个组件中显式依赖它。
您的模型将需要一个 Database 实例来建立与您的数据库的连接,这可以从 dbApi.database 获取。
import play.api.db.evolutions.EvolutionsComponents
import play.api.db.DBComponents
import play.api.db.Database
import play.api.db.HikariCPComponents
import play.api.routing.Router
import play.api.ApplicationLoader.Context
import play.api.BuiltInComponentsFromContext
import play.filters.HttpFiltersComponents
class AppComponents(cntx: Context)
extends BuiltInComponentsFromContext(cntx)
with DBComponents
with EvolutionsComponents
with HikariCPComponents
with HttpFiltersComponents {
// this will actually run the database migrations on startup
applicationEvolutions
}§演变脚本
Play 使用多个演变脚本跟踪您的数据库演变。这些脚本是用纯 SQL 编写的,默认情况下,应该位于应用程序的 `conf/evolutions/{数据库名称}` 目录中。如果演变适用于您的默认数据库,则此路径为 `conf/evolutions/default`。
第一个脚本名为 `1.sql`,第二个脚本名为 `2.sql`,依此类推…
每个脚本包含两个部分
- **Ups** 部分描述了所需的转换。
- **Downs** 部分描述了如何撤销它们。
例如,看看这个引导基本应用程序的第一个演变脚本
-- Users schema
-- !Ups
CREATE TABLE User (
id bigint(20) NOT NULL AUTO_INCREMENT,
email varchar(255) NOT NULL,
password varchar(255) NOT NULL,
fullname varchar(255) NOT NULL,
isAdmin boolean NOT NULL,
PRIMARY KEY (id)
);
-- !Downs
DROP TABLE User;
**Ups** 和 **Downs** 部分使用标准的单行 SQL 注释在您的脚本中分隔,分别包含 `!Ups` 或 `!Downs`。SQL92 ( `--` ) 和 MySQL ( `#` ) 注释样式都支持,但我们建议使用 SQL92 语法,因为它受更多数据库支持。
Play 在执行 `sql` 文件之前,会将它们分成一系列以分号分隔的语句,然后逐个执行。因此,如果您需要在语句中使用分号,请使用 `;;` 而不是 `;` 来转义它。例如,`INSERT INTO punctuation(name, character) VALUES ('semicolon', ';;');`。
如果在 `application.conf` 中配置了数据库并且存在演变脚本,则演变会自动激活。您可以通过设置 `play.evolutions.enabled=false` 来禁用它们。例如,当测试设置自己的数据库时,您可以禁用测试环境的演变。
当演变被激活时,Play 会在 DEV 模式下每次请求之前,或在 PROD 模式下启动应用程序之前检查您的数据库模式状态。在 DEV 模式下,如果您的数据库模式未更新,则错误页面会建议您通过运行相应的 SQL 脚本同步您的数据库模式。
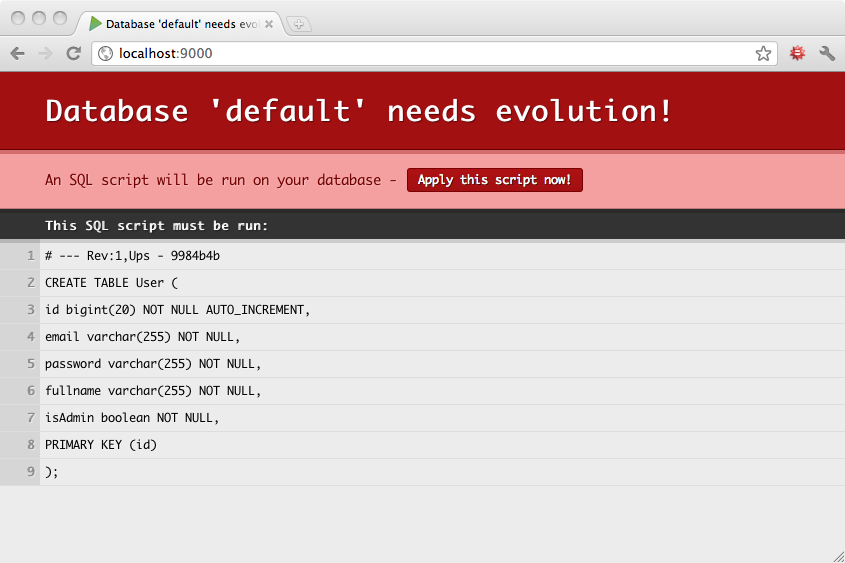
如果您同意 SQL 脚本,您可以通过单击“应用演变”按钮直接应用它。
§演变配置
演变可以在全局和每个数据源级别进行配置。对于全局配置,键应该以 `play.evolutions` 为前缀。对于每个数据源配置,键应该以 `play.evolutions.db.<datasourcename>` 为前缀,例如 `play.evolutions.db.default`。支持以下配置选项
enabled- 是否启用演进。如果在全局配置中设置为 false,则会完全禁用演进模块。默认值为 true。schema- 生成的演进和锁定表将保存到的数据库模式。默认情况下没有设置模式。metaTable- 用于存储演进元数据的表。默认情况下为play_evolutions。autocommit- 是否应使用自动提交。如果为 false,则演进将在单个事务中应用。默认值为 true。useLocks- 是否应使用锁定表。如果您有多个可能运行演进的 Play 节点,但希望确保只有一个节点运行,则必须使用此选项。它将创建一个与您的演进元数据表同名的表,并带有_lock后缀(默认为play_evolutions_lock),并使用SELECT FOR UPDATE NOWAIT或SELECT FOR UPDATE来锁定它。这仅适用于 Postgres、Oracle 和 MySQL InnoDB。它不适用于其他数据库。默认值为 false。autoApply- 是否应自动应用演进。在开发模式下,这将导致向上和向下演进都被自动应用。在生产模式下,它将导致仅向上演进被自动应用。默认值为 false。autoApplyDowns- 是否应自动应用向下演进。在生产模式下,这将导致向下演进被自动应用。在开发模式下没有影响。默认值为 false。path- 类路径或文件系统上演进脚本的路径。默认值为evolutions。请参阅“演进脚本的位置”。substitutions.mappings- 变量(不带前缀和后缀)与其替换的映射。默认情况下没有设置映射。请参阅“变量替换”。substitutions.prefix- 用于占位符语法的首缀。默认值为$evolutions{{{。请参阅“变量替换”。substitutions.suffix- 用于占位符语法的后缀。默认值为}}}。请参阅“变量替换”。substitutions.escapeEnabled- 是否启用通过语法!$evolutions{{{...}}}对变量进行转义。默认值为true。请参阅“变量替换”。
例如,要为所有演变启用 autoApply,您可以在 application.conf 或系统属性中设置 play.evolutions.autoApply=true。要为名为 default 的数据源禁用自动提交,您需要设置 play.evolutions.db.default.autocommit=false。
§演变脚本的位置
如前所述,演变脚本默认位于应用程序的 conf/evolutions/{数据库名称} 目录中。但是,您可以更改文件夹的名称:例如,如果您希望将默认数据库的脚本存储在 conf/db_migration/default 中,您可以通过设置 path 配置来实现。
# For the default database
play.evolutions.db.default.path = "db_migration"
# Or, if you want to set the location for all databases
play.evolutions.db.path = "db_migration"
Play 始终可以加载这些脚本,因为 conf 文件夹的内容在开发模式和 生产模式 中都位于类路径上。
您也可以将演变脚本存储在项目文件夹之外,并使用绝对路径或相对路径引用它们。
# Absolute path:
play.evolutions.db.default.path = "/opt/db_migration"
# Relative path (as seen from your project's root folder)
play.evolutions.db.default.path = "../db_migration"
但是,请注意,当使用此类配置时,如果您决定捆绑一个生产包,演变脚本将不会包含在其中,因此您需要负责在生产环境中管理演变脚本。
最后,您可以将演变脚本存储在项目中,但不在 conf 文件夹中。
play.evolutions.db.default.path = "./db_migration"
在这种情况下,脚本将不会位于类路径上。在开发过程中,这并不重要,因为在查找类路径上的演变脚本之前,Play 会在文件系统上查找它们(这就是上面绝对路径和相对路径方法有效的原因)。
但是,如果演变文件夹没有放在 conf 目录中,因此也不在类路径上,这意味着它不会被打包到生产环境中。为了确保文件夹被打包并在生产环境中可用,您需要在 build.sbt 中进行设置。
Universal / mappings ++= (baseDirectory.value / "db_migration" ** "*").get.map {
(f: File) => f -> f.relativeTo(baseDirectory.value).get.toString
}
§变量替换
您可以在演变脚本中定义占位符,这些占位符将被替换为在 application.conf 中定义的替换值。
play.evolutions.db.default.substitutions.mappings = {
table = "users"
name = "John"
}
例如,一个演变脚本像这样:
INSERT INTO $evolutions{{{table}}}(username) VALUES ('$evolutions{{{name}}}');
现在将变成
INSERT INTO users(username) VALUES ('John');
在演变应用时。
演变元表将包含原始 SQL 脚本,不包含已替换的占位符。
变量替换不区分大小写,因此 $evolutions{{{NAME}}} 与 $evolutions{{{name}}} 相同。
您也可以更改占位符语法的 前缀 和 后缀
# Change syntax to @{...}
play.evolutions.db.default.substitutions.prefix = "@{"
play.evolutions.db.default.substitutions.suffix = "}"
进化模块还支持转义,用于变量不应该被替换的情况。这种转义机制默认启用。要禁用它,您需要设置
play.evolutions.db.default.substitutions.escapeEnabled = false
如果启用,语法 !$evolutions{{{...}}} 可用于转义变量替换。例如
INSERT INTO notes(comment) VALUES ('!$evolutions{{{comment}}}');
不会被替换为它的替换,而是会变成
INSERT INTO notes(comment) VALUES ('$evolutions{{{comment}}}');
在最终的 sql 中。
这种转义机制将应用于所有
!$evolutions{{{...}}}占位符,无论在substitutions.mappings配置中是否定义了变量的映射。
§同步并发更改
现在让我们假设我们有两个开发人员正在从事这个项目。Jamie 将开发一个需要新数据库表的特性。因此 Jamie 将创建以下 2.sql 进化脚本
-- Add Post
-- !Ups
CREATE TABLE Post (
id bigint(20) NOT NULL AUTO_INCREMENT,
title varchar(255) NOT NULL,
content text NOT NULL,
postedAt date NOT NULL,
author_id bigint(20) NOT NULL,
FOREIGN KEY (author_id) REFERENCES User(id),
PRIMARY KEY (id)
);
-- !Downs
DROP TABLE Post;
Play 将将此进化脚本应用于 Jamie 的数据库。
另一方面,Robin 将开发一个需要更改 User 表的特性。因此 Robin 也将创建以下 2.sql 进化脚本
-- Update User
-- !Ups
ALTER TABLE User ADD age INT;
-- !Downs
ALTER TABLE User DROP age;
Robin 完成了特性并提交(假设使用 Git)。现在 Jamie 必须在继续之前合并 Robin 的工作,因此 Jamie 运行 git pull,合并出现冲突,例如
Auto-merging db/evolutions/2.sql
CONFLICT (add/add): Merge conflict in db/evolutions/2.sql
Automatic merge failed; fix conflicts and then commit the result.
每个开发人员都创建了一个 2.sql 进化脚本。因此 Jamie 需要合并此文件的内容
<<<<<<< HEAD
-- Add Post
-- !Ups
CREATE TABLE Post (
id bigint(20) NOT NULL AUTO_INCREMENT,
title varchar(255) NOT NULL,
content text NOT NULL,
postedAt date NOT NULL,
author_id bigint(20) NOT NULL,
FOREIGN KEY (author_id) REFERENCES User(id),
PRIMARY KEY (id)
);
-- !Downs
DROP TABLE Post;
=======
-- Update User
-- !Ups
ALTER TABLE User ADD age INT;
-- !Downs
ALTER TABLE User DROP age;
>>>>>>> devB
合并非常容易
-- Add Post and update User
-- !Ups
ALTER TABLE User ADD age INT;
CREATE TABLE Post (
id bigint(20) NOT NULL AUTO_INCREMENT,
title varchar(255) NOT NULL,
content text NOT NULL,
postedAt date NOT NULL,
author_id bigint(20) NOT NULL,
FOREIGN KEY (author_id) REFERENCES User(id),
PRIMARY KEY (id)
);
-- !Downs
ALTER TABLE User DROP age;
DROP TABLE Post;
此进化脚本代表数据库的新修订版 2,它与 Jamie 已经应用的先前修订版 2 不同。
因此 Play 将检测到它并要求 Jamie 同步数据库,首先撤消已经应用的旧修订版 2,然后应用新的修订版 2 脚本
§不一致的状态
有时您会在进化脚本中犯错,它们会失败。在这种情况下,Play 将标记您的数据库模式处于不一致状态,并要求您在继续之前手动解决问题。
例如,此进化的 Ups 脚本存在错误
-- Add another column to User
-- !Ups
ALTER TABLE Userxxx ADD company varchar(255);
-- !Downs
ALTER TABLE User DROP company;
因此尝试应用此进化将失败,Play 将标记您的数据库模式为不一致
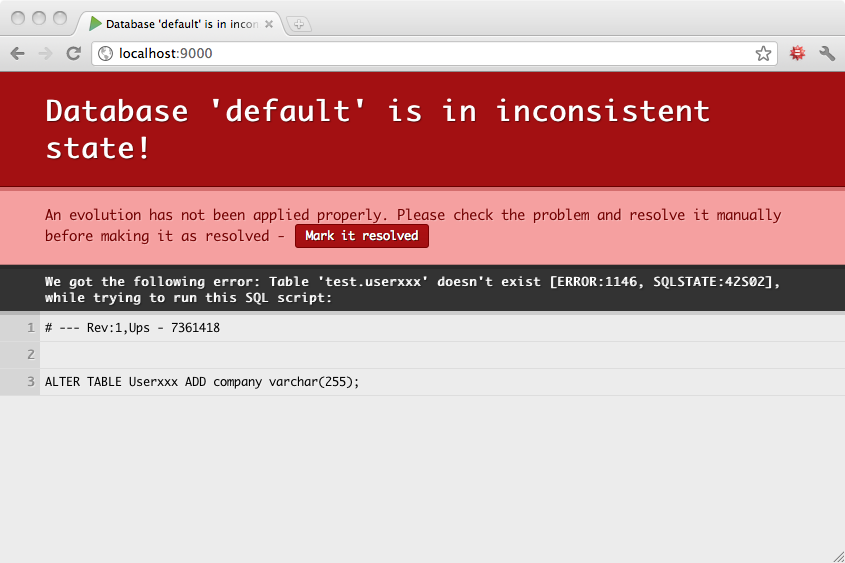
现在,在继续之前,您必须修复此不一致。因此您运行修复后的 SQL 命令
ALTER TABLE User ADD company varchar(255);
… 然后通过单击按钮将此问题标记为手动解决。
但是由于您的进化脚本存在错误,您可能希望修复它。因此您修改 3.sql 脚本
-- Add another column to User
-- !Ups
ALTER TABLE User ADD company varchar(255);
-- !Downs
ALTER TABLE User DROP company;
Play 检测到此新的进化,它替换了之前的 3 个进化,并将运行相应的脚本。现在一切都已修复,您可以继续工作。
然而,在开发模式下,通常更简单的方法是直接清空开发数据库,然后从头开始重新应用所有演变。
§事务性 DDL
默认情况下,每个演变脚本的每个语句都会立即执行。如果您的数据库支持 事务性 DDL,您可以在 application.conf 中设置 evolutions.autocommit=false 来更改此行为,从而使 **所有** 语句都在 **一个事务** 中执行。现在,当演变脚本在禁用自动提交的情况下无法应用时,整个事务将回滚,并且不会应用任何更改。因此,您的数据库将保持“干净”,并且不会变得不一致。这使您可以轻松地修复演变脚本中的任何 DDL 问题,而无需像上面描述的那样手动修改数据库。
§演变存储和限制
演变存储在您数据库中的一个名为 play_evolutions 的表中。一个 Text 列存储实际的演变脚本。您的数据库可能对 Text 列有 64kb 的大小限制。为了解决 64kb 的限制,您可以:手动更改 play_evolutions 表的结构,更改列类型,或者(首选)创建多个大小小于 64kb 的演变脚本。
下一步:服务器后端
发现此文档中的错误?此页面的源代码可以在 这里 找到。在阅读了 文档指南 之后,请随时贡献一个拉取请求。有疑问或建议要分享?请访问 我们的社区论坛,与社区开始对话。