

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
§访问 SQL 数据库
注意:JDBC 是一个阻塞操作,会导致线程等待。在控制器中直接运行 JDBC 查询会对 Play 应用程序的性能产生负面影响!请参阅“配置自定义 ExecutionContext”部分。
§配置 JDBC 连接池
Play 提供了一个插件来管理 JDBC 连接池。您可以根据需要配置任意数量的数据库。
要启用数据库插件,请添加构建依赖项
- Java
-
libraryDependencies ++= Seq( javaJdbc ) - Scala
-
libraryDependencies ++= Seq( jdbc )
§配置 JDBC 驱动程序依赖项
Play 不提供任何数据库驱动程序。因此,要在生产环境中部署,您需要将数据库驱动程序添加为应用程序依赖项。
例如,如果您使用 MySQL5,则需要添加一个 依赖项 用于连接器
libraryDependencies ++= Seq(
"com.mysql" % "mysql-connector-j" % "8.0.33"
)§数据库配置
然后,您必须在 conf/application.conf 文件中配置连接池。按照惯例,默认 JDBC 数据源必须称为 default,相应的配置属性为 db.default.driver 和 db.default.url。
# Default database configuration
db.default.driver=org.h2.Driver
db.default.url="jdbc:h2:mem:play"
如果配置不正确,您将在浏览器中直接收到通知
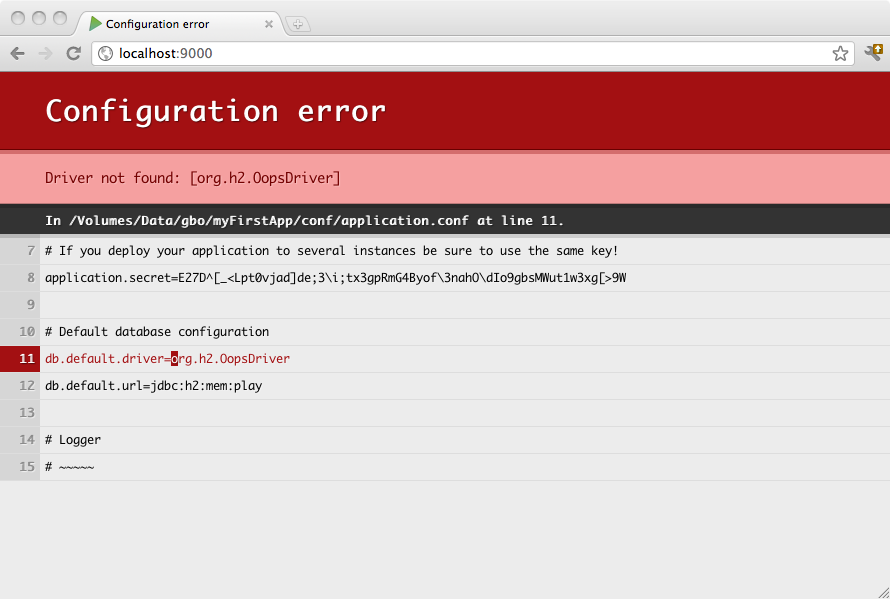
您也可以通过设置 play.db.default 来更改 default 名称,例如
play.db.default = "primary"
db.primary.driver=org.h2.Driver
db.primary.url="jdbc:h2:mem:play"
§如何配置多个数据源
要配置多个数据源
# Orders database
db.orders.driver=org.h2.Driver
db.orders.url="jdbc:h2:mem:orders"
# Customers database
db.customers.driver=org.h2.Driver
db.customers.url="jdbc:h2:mem:customers"
§H2 数据库引擎连接属性
内存数据库
# Default database configuration using H2 database engine in an in-memory mode
db.default.driver=org.h2.Driver
db.default.url="jdbc:h2:mem:play"
基于文件的数据库
# Default database configuration using H2 database engine in a persistent mode
db.default.driver=org.h2.Driver
db.default.url="jdbc:h2:/path/to/db-file"
H2 数据库 URL 的详细信息可以在 H2 数据库引擎速查表 中找到。
§SQLite 数据库引擎连接属性
# Default database configuration using SQLite database engine
db.default.driver=org.sqlite.JDBC
db.default.url="jdbc:sqlite:/path/to/db-file"
§PostgreSQL 数据库引擎连接属性
# Default database configuration using PostgreSQL database engine
db.default.driver=org.postgresql.Driver
db.default.url="jdbc:postgresql://database.example.com/playdb"
§MySQL 数据库引擎连接属性
# Default database configuration using MySQL database engine
# Connect to playdb as playdbuser
db.default.driver=com.mysql.jdbc.Driver
db.default.url="jdbc:mysql://127.0.0.1/playdb"
db.default.username=playdbuser
db.default.password="a strong password"
§通过 JNDI 公开数据源
某些库期望从 JNDI 中检索 Datasource 引用。您可以通过在 conf/application.conf 中添加以下配置来通过 JNDI 公开任何 Play 管理的数据源
db.default.driver=org.h2.Driver
db.default.url="jdbc:h2:mem:play"
db.default.jndiName=DefaultDS
§如何配置 SQL 日志语句
并非所有连接池都提供(开箱即用)记录 SQL 语句的方法。例如,HikariCP 建议您使用数据库供应商的日志功能。从 HikariCP 文档
记录语句文本/慢查询日志
与语句缓存类似,大多数主要数据库供应商都通过其自身驱动程序的属性支持语句日志记录。这包括 Oracle、MySQL、Derby、MSSQL 等。有些甚至支持慢查询日志记录。我们认为这是一个“开发时”功能。对于那些不支持它的少数数据库,jdbcdslog-exp 是一个不错的选择。在开发和预生产阶段非常有用。
因此,Play 使用 jdbcdslog-exp 为支持的池启用一致的 SQL 日志语句支持。可以使用 logSql 属性按数据库配置 SQL 日志语句
# Default database configuration using PostgreSQL database engine
db.default.driver=org.postgresql.Driver
db.default.url="jdbc:postgresql://database.example.com/playdb"
db.default.logSql=true
之后,您可以根据 其手册中的说明 配置 jdbcdslog-exp 的日志级别。基本上,您需要将根记录器配置为 INFO,然后决定 jdbcdslog-exp 将记录什么(连接、语句和结果集)。以下是一个使用 logback.xml 配置日志的示例
<?xml version="1.0" encoding="UTF-8" ?>
<!--
Copyright (C) from 2022 The Play Framework Contributors <https://github.com/playframework>, 2011-2021 Lightbend Inc. <https://www.lightbend.com>
-->
<!DOCTYPE configuration>
<configuration>
<import class="ch.qos.logback.classic.encoder.PatternLayoutEncoder"/>
<import class="ch.qos.logback.classic.AsyncAppender"/>
<import class="ch.qos.logback.core.FileAppender"/>
<import class="ch.qos.logback.core.ConsoleAppender"/>
<appender name="FILE" class="FileAppender">
<file>${application.home:-.}/logs/application.log</file>
<encoder class="PatternLayoutEncoder">
<pattern>%date [%level] from %logger in %thread - %message%n%xException</pattern>
</encoder>
</appender>
<appender name="STDOUT" class="ConsoleAppender">
<encoder class="PatternLayoutEncoder">
<pattern>%highlight(%-5level) %logger{15} - %message%n%xException{10}</pattern>
</encoder>
</appender>
<appender name="ASYNCFILE" class="AsyncAppender">
<appender-ref ref="FILE"/>
</appender>
<appender name="ASYNCSTDOUT" class="AsyncAppender">
<appender-ref ref="STDOUT"/>
</appender>
<logger name="play" level="INFO"/>
<logger name="org.jdbcdslog.ConnectionLogger" level="OFF"/> <!-- Won' log connections -->
<logger name="org.jdbcdslog.StatementLogger" level="INFO"/> <!-- Will log all statements -->
<logger name="org.jdbcdslog.ResultSetLogger" level="OFF"/> <!-- Won' log result sets -->
<root level="WARN">
<appender-ref ref="ASYNCFILE"/>
<appender-ref ref="ASYNCSTDOUT"/>
</root>
</configuration>警告:请记住,这仅用于开发环境,您不应该在生产环境中配置它,因为这会导致性能下降并污染您的日志。
§访问 JDBC 数据源
Play 数据库包主要通过 Database(请参阅 Java 和 Scala 的文档)类提供对默认数据源的访问。
- Java
-
import java.util.concurrent.CompletableFuture; import java.util.concurrent.CompletionStage; import javax.inject.*; import play.db.*; @Singleton class JavaApplicationDatabase { private Database db; private DatabaseExecutionContext executionContext; @Inject public JavaApplicationDatabase(Database db, DatabaseExecutionContext context) { this.db = db; this.executionContext = executionContext; } public CompletionStage<Integer> updateSomething() { return CompletableFuture.supplyAsync( () -> { return db.withConnection( connection -> { // do whatever you need with the db connection return 1; }); }, executionContext); } } - Scala
-
import javax.inject.Inject import scala.concurrent.Future import play.api.db.Database class ScalaApplicationDatabase @Inject() (db: Database, databaseExecutionContext: DatabaseExecutionContext) { def updateSomething(): Unit = { Future { db.withConnection { conn => // do whatever you need with the db connection } }(databaseExecutionContext) } }
对于非默认数据库
- Java
-
import java.util.concurrent.CompletableFuture; import java.util.concurrent.CompletionStage; import javax.inject.Inject; import javax.inject.Singleton; import play.db.Database; import play.db.NamedDatabase; @Singleton class JavaNamedDatabase { private Database db; private DatabaseExecutionContext executionContext; @Inject public JavaNamedDatabase( // inject "orders" database instead of "default" @NamedDatabase("orders") Database db, DatabaseExecutionContext executionContext) { this.db = db; this.executionContext = executionContext; } public CompletionStage<Integer> updateSomething() { return CompletableFuture.supplyAsync( () -> db.withConnection( connection -> { // do whatever you need with the db connection return 1; }), executionContext); } } - Scala
-
import javax.inject.Inject import scala.concurrent.Future import play.api.db.Database import play.db.NamedDatabase class ScalaNamedDatabase @Inject() ( @NamedDatabase("orders") ordersDatabase: Database, databaseExecutionContext: DatabaseExecutionContext ) { def updateSomething(): Unit = { Future { ordersDatabase.withConnection { conn => // do whatever you need with the db connection } }(databaseExecutionContext) } }
在这两种情况下,当使用 withConnection 时,连接将在代码块结束时自动关闭。
§获取 JDBC 连接
您可以以相同的方式检索 JDBC 连接
- Java
-
import java.sql.Connection; import java.util.concurrent.CompletableFuture; import java.util.concurrent.CompletionStage; import javax.inject.Inject; import play.db.Database; class JavaJdbcConnection { private Database db; private DatabaseExecutionContext executionContext; @Inject public JavaJdbcConnection(Database db, DatabaseExecutionContext executionContext) { this.db = db; this.executionContext = executionContext; } public CompletionStage<Void> updateSomething() { return CompletableFuture.runAsync( () -> { // get jdbc connection Connection connection = db.getConnection(); // do whatever you need with the db connection return; }, executionContext); } } - Scala
-
import javax.inject.Inject import scala.concurrent.Future import play.api.db.Database class ScalaJdbcConnection @Inject() (db: Database, databaseExecutionContext: DatabaseExecutionContext) { def updateSomething(): Unit = { Future { // get jdbc connection val connection = db.getConnection() // do whatever you need with the db connection // remember to close the connection connection.close() }(databaseExecutionContext) } }
需要注意的是,生成的连接不会在请求周期结束时自动释放。换句话说,您有责任在代码中的某个地方调用它们的 close() 方法,以便它们可以立即返回到池中。
§使用 CustomExecutionContext
在使用 JDBC 时,您应该始终使用自定义执行上下文,以确保 Play 的渲染线程池完全专注于渲染结果并充分利用核心。您可以使用 Play 的 CustomExecutionContext(请参阅 Java 和 Scala 文档)类来配置一个专门用于服务 JDBC 操作的自定义执行上下文。有关更多详细信息,请参阅 JavaAsync/ScalaAsync 和 ThreadPools。
Play 下载页面上的所有 Play 示例模板,这些模板使用阻塞 API(例如 Anorm、JPA),都已更新为在适当的地方使用自定义执行上下文。例如
- Scala:转到 playframework/play-scala-anorm-example/ 显示 CompanyRepository 类接受一个
DatabaseExecutionContext,它包装了所有数据库操作。 - Java:转到 playframework/play-java-jpa-example 显示 JPAPersonRepository 类接受一个
DatabaseExecutionContext,它包装了所有数据库操作。
对于涉及 JDBC 连接池的线程池大小,您希望使用线程池执行器,固定线程池大小与连接池匹配。按照 HikariCP 的池大小页面 中的建议,您应该将 JDBC 连接池配置为物理核心数量的两倍,加上磁盘主轴的数量,例如,如果您有四个核心 CPU 和一个磁盘,那么池中总共有 9 个 JDBC 连接。
# db connections = ((physical_core_count * 2) + effective_spindle_count)
fixedConnectionPool = 9
database.dispatcher {
executor = "thread-pool-executor"
throughput = 1
thread-pool-executor {
fixed-pool-size = ${fixedConnectionPool}
}
}
§配置连接池
默认情况下,Play 使用 HikariCP 作为默认的数据库连接池实现。您也可以通过指定完全限定的类名来使用实现 play.api.db.ConnectionPool 的自定义连接池。
play.db.pool=your.own.ConnectionPool
可以在 Play 的 JDBC reference.conf 中的 play.db.prototype 属性中找到连接池的所有配置选项。
§测试
有关使用数据库进行测试的信息,包括如何设置内存数据库,请参见
§启用 Play 数据库演变
阅读 演变 以了解 Play 数据库演变的用途,并按照使用说明进行操作。
下一步:使用内存中的 H2 数据库
发现此文档中的错误?此页面的源代码可以在 此处 找到。阅读完 文档指南 后,请随时贡献拉取请求。有疑问或建议要分享?前往 我们的社区论坛 与社区进行交流。